Introduction
Il y a de nombreux cas ou nous pourrions écrire du code plus générique mais l’approche pojo rends compliqué cela car il faut faire au minimum de l’introspection et souvent aussi de la génération ou du proxying. La complexité des api java et l’étendu des types possible nous coupent de cette approche. Pourtant beaucoup de lib et framework utilisent ces technique et en sont tributaire. Cela va du simple parsseur de ligne de commande (picollo) a l’API web exposer via Spring en passant par Hibernate, les to/from Json, etc
Pourtant toutes ces libs ont pour fonction de manipuler de la data. Elles ne manipulent pas des objets qui portent du métier.
Avoir un framework qui expose le modèle de donnée (son schema) et permet un accès générique à la data permet de rendre les mêmes services mais avec du code beaucoup plus simple et facile a comprendre. Bien sur, l’indirection ajoutée par rapport a du code orienté pojo ajoute une complexité, mais elle n’a rien a voir avec la complexité derrière un Hibernate!
Un des inconvénient est que le code métier est moins agréable a lire.
Le framework Globs est vraiment utile si vous avez des composants qui doivent gérer des données générique par rapport a une fonction donnée. Dans beaucoup de projet, il y a une partie metamodel qui a été codée. Cette modélisation remonte plus ou moins dans les couches métiers et parfois c’est le métier qui descends dans le metamodel. Glob permet de modéliser tous les type de données standard et permet via les annotations de mettre des informations métier. Cela se fait via le GlobType qui est le schema et des Glob pour les valeurs.
API
Le schema est modélisé par l’interface GlobType:
public interface GlobType extends ... { String getName(); Field getField(String name) throws ItemNotFound; <T extends Field> T getTypedField(String name) throws ItemNotFound; Field findField(String name); boolean hasField(String name); Field[] getFields(); ... }
Les champs sont modélisé par l’interface Field et ces dérivés:
public sealed interface Field extends ... permits BooleanField, IntegerField, LongField, StringField, DoubleField, BlobField, BigDecimalField, DateField, DateTimeField, GlobField, GlobUnionField, BooleanArrayField, IntegerArrayField, LongArrayField, StringArrayField, DoubleArrayField, BigDecimalArrayField, GlobArrayField, GlobArrayUnionField { String getName(); GlobType getGlobType(); ... boolean hasAnnotation(Key key); Glob getAnnotation(Key key); ... <T extends FieldVisitor> T accept(T visitor) throws Exception;
La data est représentée par l’interface Glob :
public interface Glob extends ... { GlobType getType(); boolean isSet(Field field) throws ItemNotFound; boolean isNull(Field field) throws ItemNotFound; Object getValue(Field field) throws ItemNotFound; Double get(DoubleField field) throws ItemNotFound; double get(DoubleField field, double valueIfNull) throws ItemNotFound; double[] get(DoubleArrayField field) throws ItemNotFound; ...
A la création d’un Glob a travers sont GlobType, on obtient un MutableGlob :
public interface MutableGlob extends Glob, FieldSetter<MutableGlob> { MutableGlob unset(Field field); }
Cas d’usage
Agrégateur
Glob est utilisé pour explorer des vues en faisant du drill down pour comprendre un risque de marché (Calcul de VaR sur des gigas de données) et aussi pour explorer de la data
Il s’agit donc de “Cube”. Il faut naviguer dans des dimensions (breakdown) et agréger les outputs. Ce genre de code est toujours générique: le dictionnaire est construits a partir du metamodel des données attaché à la source et les filtres, les algo d’agrégation, les calculs spécialisés s’appuient sur ce model générique.
Par exemple dans globs-view :
ViewEngine viewEngine = new ViewEngineImpl(); Glob dictionary = viewEngine.createDictionary(ViewType1.TYPE); MutableGlob viewRequest = ViewRequestType.TYPE.instantiate(); Glob[] breakdowns = dictionary.get(DictionaryType.breakdowns); viewRequest.set(ViewRequestType.breakdowns, new Glob[]{ br("Name1", breakdowns), br("NameSub2", breakdowns), br("Name2", breakdowns), br("NameSub1", breakdowns) }); viewRequest.set(ViewRequestType.output, new Glob[]{ ViewOutput.TYPE.instantiate() .set(ViewOutput.uniqueName, br("qty", breakdowns).get(ViewBreakdown.uniqueName)) .set(ViewOutput.name, "quantity") }); ViewBuilder viewBuilder = viewEngine.buildView(dictionary, viewRequest);
Qui produit :
{
"name": "",
"nodeName": "root",
"__children__": [
{
"name": "n1",
"nodeName": "Name1",
"__children__": [
{
"name": "sub21",
"nodeName": "SUB2.NameSub2",
"__children__": [
{
"name": "n2",
"nodeName": "Name2",
"__children__": [
{
"name": "subN1",
"nodeName": "SUB1.NameSub1",
"output": {
"quantity": 1.0
}
}
],
"output": {
"quantity": 1.0
},
La vue sur le dictionnaire généré a partir du GlobType
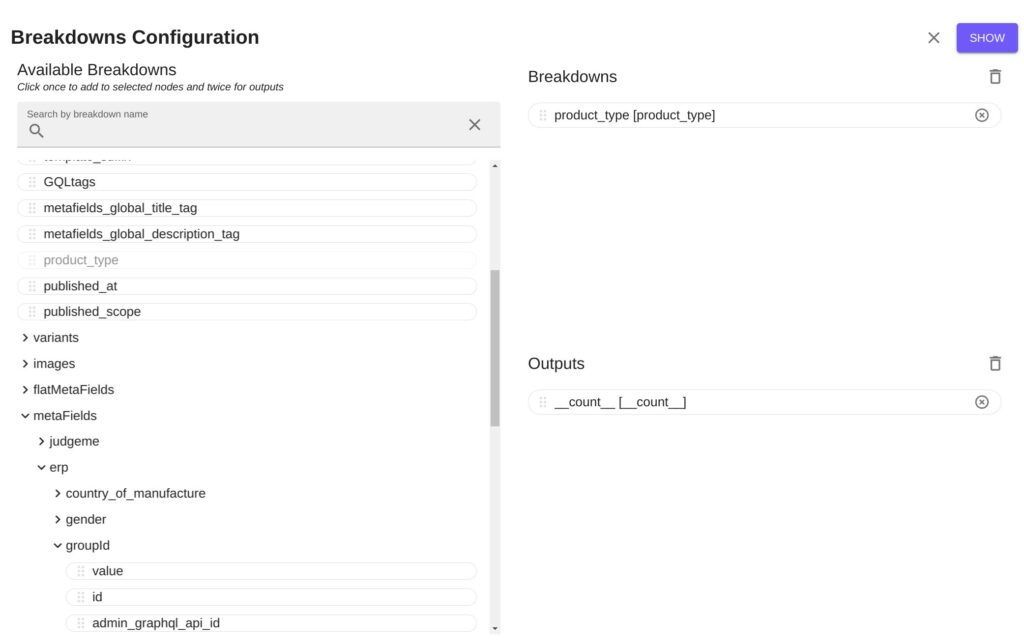
Une vue sur les données:
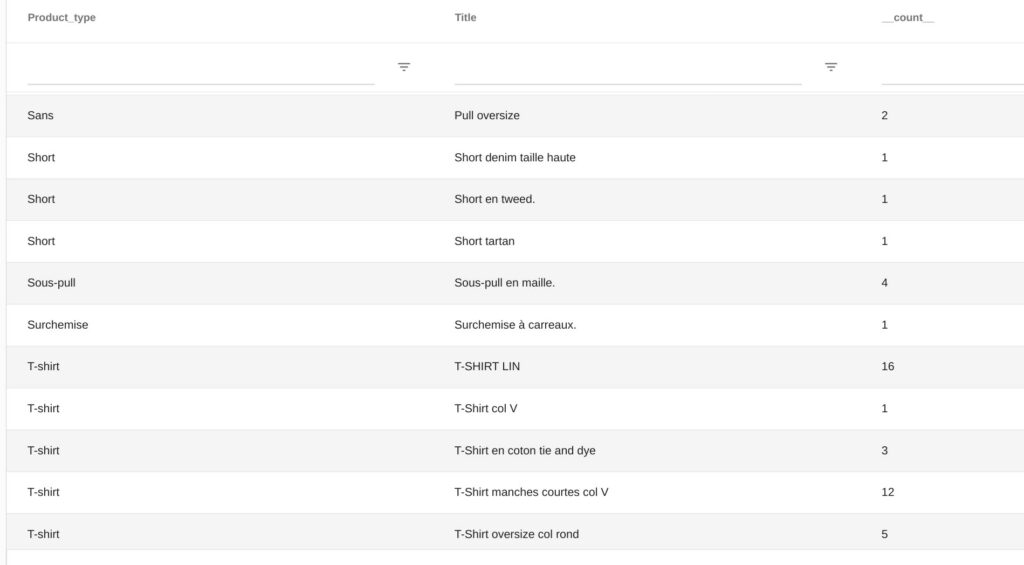
Cache/diff, listener de diff sur Shopify
Dans ce cas, on veut mettre a jour des catalogue produits volumineux et pour que nos apps interne ne réagissent que si certains champs ont changé on doit optimisé les lectures et calculer des deltas. Shopify ne nous disant pas ce qui a changé sur ces notifications et l’API ayant des “rate limit”.
Pour cela on construit un cache et on calcule le delta entre le cache et la notification pour savoir ce qui a changé. Il faut donc pour chaque type d’entité (produit, order, customer, etc) avoir un cache de la data (en mémoire ou sur disque) et parcourir les champs pour trouver ceux qui ont changé, matcher cela a une requête d’écoute afin de notifier la bonne application.
Ce genre de code est par essence générique et Glob répond bien au problème.
Exemple d’output produit (sur le topic kafka):
{
"_kind": "changeEventsType",
"id": 176771,
"name": "MJDXfpqBb58TxzUvwZcco24NLvA.",
"events": [
{
"key": {
"_kind": "product",
"id": 9249391051087
},
"create": [],
"delete": [],
"update": [
{
"oldValues": {
"_kind": "shopifyMetaFieldType",
"value": "[\"NSXX\",\"FR02\",\"LN30\",\"ST01\",\"BLXX\"]",
"updated_at": "2024-05-08T01:45:01+02:00"
},
"newValues": {
"_kind": "shopifyMetaFieldType",
"id": 42340288463183,
"admin_graphql_api_id": "gid://shopify/Metafield/42340288463183",
"owner_resource": "product",
"owner_id": 9249391051087,
"namespace": "erp",
"key": "maintenance_type",
"value": "[\"NSXX\",\"BLXX\",\"FR02\",\"ST01\",\"LN30\"]",
"description": null,
"type": "list.single_line_text_field",
"created_at": "2024-05-03T01:45:03+02:00",
"updated_at": "2024-06-13T01:45:02+02:00"
}
}
]
}
]
}
front générique pour éditer des configurations
On veut configurer des taches dans un workflow. Pour cela chaque tache expose son schema (GlobType) et le front construit les composants et redescends un Glob.
Une data comme :
{
"mapping": {
"productKeyFieldName": "erp_product_id",
"variantSkuFieldName": "sku",
"mappings": [
{
"productMetaFieldMapping": {
"sourceField": "erp_product_id",
"namespaceField": "erp",
"keyField": "erp_product_id",
"type": "single_line_text_field",
"valuesToIgnore": [],
"description": ""
}
},
est affiché comme ca :
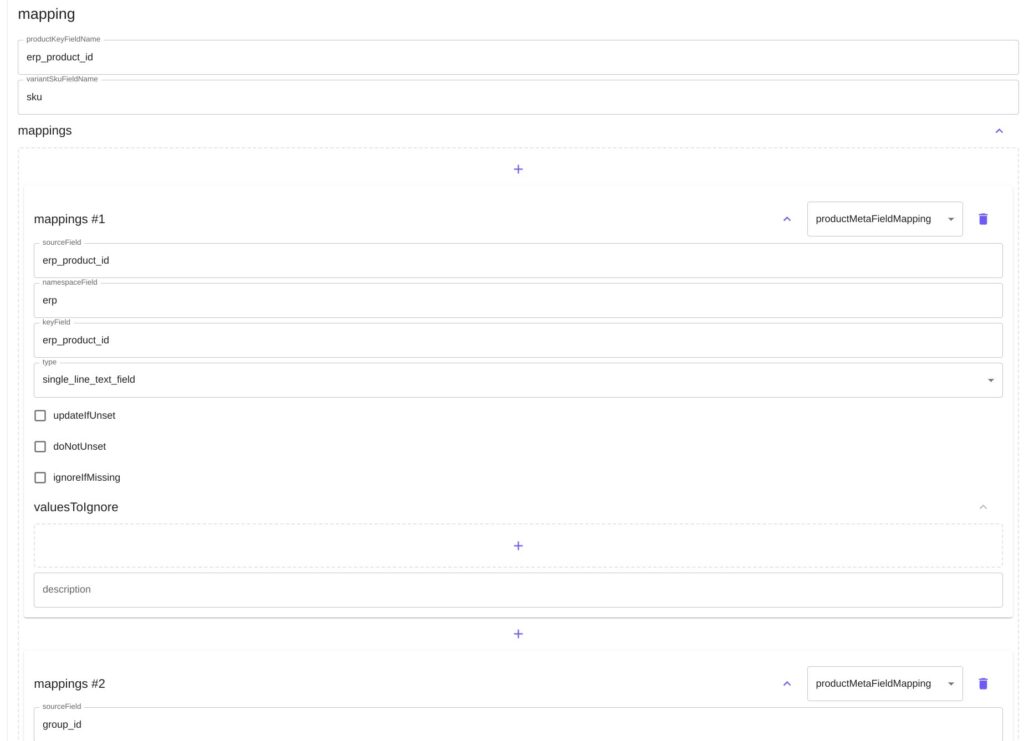
Son schéma étant :
public class ImportMapping { public static GlobType TYPE; @FieldNameAnnotation("productKeyFieldName") public static StringField productKeyFieldName; @FieldNameAnnotation("variantSkuFieldName") public static StringField variantSkuFieldName; @Targets({DirectProductMapping.class, ProductMetaFieldMapping.class, ProductListMetaFieldMapping.class, ProductTagMapping.class, DirectVariantMapping.class, VariantOptionMapping.class, VariantMetaFieldMapping.class}) public static GlobArrayUnionField mappings; static { GlobTypeLoaderFactory.create(ImportMapping.class).load(); } }
On voit par ce dernier exemple qu’on peut travailler aussi en mode typée, même si le code est moins agréable a lire qu’en pleine pojo.
public ImportCatalog(ShopifyCall shopifyCall, ShopifyClientAccess shopifyClientAccess, Glob config, ... this.mapping = Arrays.asList(config.getOrEmpty(ImportMapping.mappings)); this.productKey = config.getNotNull(ImportMapping.productKeyFieldName); this.variantKey = config.get(ImportMapping.variantSkuFieldName);
Ces exemples montrent divers usages en production de ce framework.